Miscellaneous stuff around HPC Scheduling and Batch Systems.
How to integrate an On-demand file system into SLURM can be found here
A more addvanced exmaple on how to apply a submitfilter to Moab is aavailable here
On Demand File System (BeeGFS) integration into SLURM
In modern HPC systems, parallel (distributed) file systems, like Lustre, BeeGFS and IBM Spectrum scale are used as storage file systems. However, I/O performance of HPC systems has failed to keep up with the increase in computational power. As a result, the I/O subsystem is often the bottleneck of the entire HPC system. At the same time, (NVMe)-SSDs are emering into the compute nodes. These SSDs are usually only visiable within a compute node and for parallel distributed jobs. These node-local SSDs can be used as storage for a BeeGFS On-demand (BeeOND) file systems
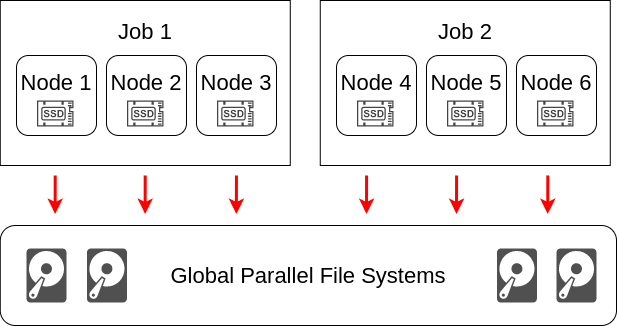
Figures illustrates the concept. Here are two jobs which allocate three nodes each. In the above picture, jobs write directly to the global parallel file system. In the picture below, a private parallel file system is created for each job. This private ODFS is only available on the allocated nodes of a job and uses the node-local storage (in this case the SSDs).
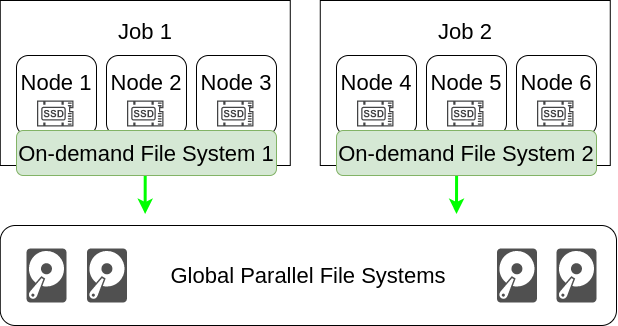
Before we integrate BeeOND ( BeeGFS ON Demand) into the Slurm batch system, make sure BeeOND/BeeGFS is working when using manual. Read the BeeOND docs for installation and testing. It is recommend to have pdsh installed.
#Manual testing
root@node01:~$ cat mynodefile
node1
node2
node3
node4
#create directories on all nodes
#/mnt/odfs is going to be the mountpoint for the file system
#BeeGFS will store the data in /mnt/beeond
root@node01:~$ pdsh -w node0[1-4] mkdir /mnt/odfs /mnt/beeond
#-P to test that everything works fine with pdsh, if pdfs is not availbale dont use -P
root@node01:~$ beeond start -n mynodefile -d /mnt/beeond -c /mnt/odfs -P
root@node01:~$ df -h /mnt/odfs
beegfs_ondemand 1000G 7,2G 993G 1% /mnt/odfs
#You should be able to read and write in /mnt/odfs from all nodes (node[1-4])
First create on all nodes /etc/odfs/odfs.conf:
#Where ot mount that loopback image
#!!!! create /mnt/loop42 on all nodes
ODFSLOOPBACKMOUNTPOINT=/mnt/loop42
#Location of image file
#Basenames $JOB_ID added to follow configs
ODFSIMAGE=/tmp/odfs.img.${SLURM_JOB_ID}
ODFSNODEFILE=/tmp/nodefile.odfs.${SLURM_JOB_ID}
#!!!! create /mnt/odfs dir on all nodes
ODFSMOUNTPOINT=/mnt/odfs/${SLURM_JOB_ID}
ODFSSTATUSFILE=/tmp/odfs-status.${SLURM_JOB_ID}
#configure connection-based authentication file
ODFSCONNAUTHFILE=/tmp/odfs_caf
#################################
#Which filesystem to put on imagefile
ODFSMKFSTYPE=/sbin/mkfs.xfs
#Quiet
ODFSMKFSOPTION=-q
#mountoptions
ODFSMOUNTOPTION=-onoatime,nodiratime,logbufs=8,logbsize=256k,largeio,inode64,swalloc,allocsize=131072k,loop
#Size of image file, dd seek used, file will increase with usage
#
ODFSIMAGESIZE=250G
Create a a helper script on all nodes /etc/odfs/functions.sh:
function odfs_create_loopmount() {
dd if=/dev/zero of=${ODFSIMAGE} bs=1 count=0 seek=${ODFSIMAGESIZE} status=none
${ODFSMKFSTYPE} ${ODFSMKFSOPTION} ${ODFSIMAGE}
mount ${ODFSMOUNTOPTION} ${ODFSIMAGE} ${ODFSLOOPBACKMOUNTPOINT}
}
function odfs_remove_loopmount() {
i=0
while [[ $i -le 5 ]]
do
# Sometimes BeeOND just hangs
# Try a few times then give up
odfs_kill_beeond
sleep 3
mountpoint -q ${ODFSMOUNTPOINT}
if [[ "$?" -ne "0" ]]
then
break
fi
i=$[$i+1]
done
#message "removing loopmount"
k=0
while [[ $k -le 5 ]]
do
logger "running umount on ${ODFSLOOPBACKMOUNTPOINT}"
/usr/bin/umount -d -f -v ${ODFSLOOPBACKMOUNTPOINT}
sleep 1
mountpoint -q ${ODFSLOOPBACKMOUNTPOINT}
if [[ "$?" -ne "0" ]]
then
break
fi
k=$[$k+1]
done
rm ${ODFSIMAGE}
}
function odfs_kill_beeond() {
/usr/bin/beeond stoplocal -i /tmp/beeond.tmp -q -L -c -u
killall -q /opt/beegfs/sbin/beegfs-storage
killall -q /opt/beegfs/sbin/beegfs-helperd
killall -q /opt/beegfs/sbin/beegfs-mgmtd
killall -q /opt/beegfs/sbin/beegfs-meta
/usr/sbin/rmmod beegfs
rm /tmp/beeond.tmp
#logger "rmmod beegfs"
}
function odfs_stop_beeond() {
#user requested adafs and now stop it
#try the nice way
#/usr/bin/beeond stop -q -n ${ODFSNODEFILE} -i /tmp/beeond.tmp -L -c
logger "odfs stopping beenod"
/usr/bin/beeond stoplocal -q -i /tmp/beeond.tmp -L -c -u
rm ${ODFSNODEFILE} ${ODFSSTATUSFILE}
}
Next add these two functions to your prolog/epilogue. Here some modifications have to be done, based on your setup. /etc/slurm/prolog
function start_odfs() {
if [[ ${SLURM_JOB_CONSTRAINTS} =~ "BEEOND" ]] ; then
source /etc/odfs/odfs.conf
source /etc/odfs/functions.sh
#Enable Debug for some output
ODFSDEBUG=0
ODFSDEBUGLOG=/tmp/odfs-slurm.$SLURM_JOB_ID
if [[ $ODFSDEBUG == 1 ]];then
#create file initial
echo "prolog beeond AAAA" > $ODFSDEBUGLOG
echo "constraint found $SLURM_JOB_ID" >> $ODFSDEBUGLOG
fi
job_hosts=`scontrol show hostnames`
head_node=`echo $job_hosts | awk '{print $1;}'`
if [[ $ODFSDEBUG == 1 ]];then
echo $job_hosts >> $ODFSDEBUGLOG
echo $head_node >> $ODFSDEBUGLOG
export >> $ODFSDEBUGLOG
fi
#Create dd-imagefile and loopback mountpoint if configured on every node
if [[ ${ODFSLOOPBACK} == 1 ]]; then
#This prologue must run on all allocated nodes
#check your slurm config
odfs_create_loopmount
fi
#Create nodefile for BeeOND
#nodefile=/tmp/odfs-slurm-nodelist.$SLURM_JOB_ID
echo $job_hosts | tr " " "\n" > $ODFSNODEFILE 2>&1
#Start beeond only of job master node
if [[ ${SLURMD_NODENAME} == $head_node ]] ; then
#create connauthfile, need pdcp to distribute
#define in odfs.conf -> ODFSCONNAUTHFILE=/tmp/odfs_caf
# only for advanced security, comment if not needed
RANDOMCRED=`/usr/bin/openssl rand -base64 12`
CRED="${SLURM_JOB_ID}-${RANDOMCRED}"
echo ${CRED} > ${ODFSCONNAUTHFILE}
chmod 600 ${ODFSCONNAUTHFILE}
pdcp -w ${SLURM_JOB_NODELIST} ${ODFSCONNAUTHFILE} ${ODFSCONNAUTHFILE}
##########################################################################
#Start beeond
/usr/bin/beeond start -n ${ODFSNODEFILE} -d ${ODFSLOOPBACKMOUNTPOINT} -c ${ODFSMOUNTPOINT} -i /tmp/beeond.tmp -P -F -L /tmp
fi
#remount nosuid nodev
mount -o remount,nosuid,nodev ${ODFSMOUNTPOINT}
if [[ ${SLURMD_NODENAME} == $head_node ]] ; then
### Create multiple dirs with different stripe count for more convience
mkdir ${ODFSMOUNTPOINT}/stripe_1
/usr/bin/beegfs-ctl --setpattern --numtargets=1 --mount=${ODFSMOUNTPOINT} ${ODFSMOUNTPOINT}/stripe_1 > /dev/null 2>&1
mkdir ${ODFSMOUNTPOINT}/stripe_8
/usr/bin/beegfs-ctl --setpattern --numtargets=8 --mount=${ODFSMOUNTPOINT} ${ODFSMOUNTPOINT}/stripe_8 > /dev/null 2>&1
mkdir ${ODFSMOUNTPOINT}/stripe_16
/usr/bin/beegfs-ctl --setpattern --numtargets=16 --mount=${ODFSMOUNTPOINT} ${ODFSMOUNTPOINT}/stripe_16 > /dev/null 2>&1
mkdir ${ODFSMOUNTPOINT}/stripe_32
/usr/bin/beegfs-ctl --setpattern --numtargets=32 --mount=${ODFSMOUNTPOINT} ${ODFSMOUNTPOINT}/stripe_32 > /dev/null 2>&1
mkdir ${ODFSMOUNTPOINT}/stripe_default
#/usr/bin/beegfs-ctl --setpattern --numtargets=4 --mount=${ODFSMOUNTPOINT} ${ODFSMOUNTPOINT}/stripe_default > /dev/null 2>&1
chown ${SLURM_JOB_USER} ${ODFSMOUNTPOINT}/stripe_1 ${ODFSMOUNTPOINT}/stripe_8 ${ODFSMOUNTPOINT}/stripe_16 ${ODFSMOUNTPOINT}/stripe_32 ${ODFSMOUNTPOINT}/stripe_default
fi
#Create Status file for cleanup in epilog
echo "USER: ${SLURM_JOB_USER}" > ${ODFSSTATUSFILE}
echo "JOBID: ${SLURM_JOB_ID}" >> ${ODFSSTATUSFILE}
echo "MOUNTPOINT: ${ODSMOUNTPOINT}" >> ${ODFSSTATUSFILE}
chmod 700 ${ODFSSTATUSFILE}
chmod 700 ${ODFSDEBUGLOG}
echo "export ODFS=${ODFSMOUNTPOINT}"
fi
}
#This looks strange probbaly add just
# start_odfs
#at the end of your prolog file
start_odfs
/etc/slurm/epilog
function stop_odfs() {
#Little bit messy, SLURM_JOB_CONSTRAINTS not available in epilog
#so we are checking for the odfs Status file
source /etc/odfs/odfs.conf
ODFSDEBUG=1
if [[ -r ${ODFSSTATUSFILE} ]] ; then
source /etc/odfs/odfs.conf
source /etc/odfs/functions.sh
ODFSDEBUGLOG=/tmp/odfs-slurm.$SLURM_JOB_ID
if [[ $ODFSDEBUG == 1 ]];then
echo "EPILOGUE prolog beeond AAAA" >> $ODFSDEBUGLOG
export >> $ODFSDEBUGLOG
fi
job_hosts=`scontrol show hostnames`
head_node=`echo $job_hosts | awk '{print $1;}'`
if [[ $DEBUG == 1 ]];then
echo $job_hosts >> $ODFSDEBUGLOG
echo $head_node >> $ODFSDEBUGLOG
export >> $ODFSDEBUGLOG
fi
#First stop beeond, we are doing quick stoplocal
#make sure epilogue is executed on all nodes
odfs_stop_beeond
odfs_kill_beeond
odfs_remove_loopmount
fi
#removing probably leftover files
rm -r ${ODFSIMAGE} ${ODFSNODEFILE} ${ODFSMOUNTPOINT} ${ODFSSTATUSFILE} ${ODFSCONNAUTHFILE}
#rm ${ODFSIMAGE} ${ODFSNODEFILE} ${ODFSMOUNTPOINT} ${ODFSSTATUSFILE} ${ODFSSTATUSFILE} ${ODFSDEBUGLOG}
#only remove status files if ODFSDEBUG is not enabled
if [[ $ODFSDEBUG == 0 ]];then
rm ${ODFSSTATUSFILE} ${ODFSDEBUGLOG}
fi
#This looks strange probbaly add just
# start_odfs
#at the end of your epilog file
stop_odfs
}
Now the a constraint has to be added to slurm config, so a user can request beeond while job submission
NodeName=node[001-100] Feature=BEEOND
Now a user should just –constrain on the CLI to the sbatch command or in his jobfiles
#!/bin/bash
#SBATCH ...
#SBATCH --constraint=BEEOND
and slurm will create an ODFS for the User which can be accesses within his job. After the job has started Beeond can be found in /mnt/odfs/$SLURM_JOB_ID directory. Within the mountpoint three pre-configured directories are available:
#for small files (stripe count = 1)
/mnt/odfs/$SLURM_JOB_ID/stripe_1
#stripe count = 4
/mnt/odfs/$SLURM_JOB_ID/stripe_default
#stripe count = 8, 16 or 32, use these directories for medium sized
#and large files or when using MPI-IO
/mnt/odfs/$SLURM_JOB_ID/stripe_8
/mnt/odfs/$SLURM_JOB_ID/stripe_16
/mnt/odfs/$SLURM_JOB_ID/stripe_32
If you request less nodes than stripe count, the stripe count will be max number of nodes, e.g., You only request 8 nodes , so the directory with stripe count 16 is basically only with a stripe count 8.
The capacity of the private file system depends on the number of nodes. For each node you get 250Gbyte.
!!! Be careful when creating large files, use always the directory with the max stripe count for large files. If you create large files use a higher stripe count. For example, if your largest file is 1.1 Tb, then you have to use a stripe count larger>4 (4 x 250GB).
If you request 100 nodes for your job, the private file system is 100 * 250 Gbyte ~ 25 Tbyte (approx) capacity.
Recommendation:
The private file system is using its own metadata server. This metadata server is started on the first nodes. Depending on your application, the metadata server is consuming decent amount of CPU power. Probably adding a extra node to your job could improve the usability of the on-demand file system. Start your application with the MPI option:
mpirun -nolocal myapplication With the -nolocal option the node where mpirun is initiated is not used for your application. This node is fully available for the meta data server of your requested on-demand file system.
Moab Submitfilter
Moab is offering a submitfilter to modify the job xml data before submitting to the Moab scheduler. More about the submitfilter can be found in the MOAB docs
Below is an example for such a submitfilter. Just add it to MOAB configuration with
SUBMITFILTER /etc/some/path/filter.pl
This is a exmaple for a submitfilter that worked with older (7.x) versions of Moab. Be careful when using it with newer versions. Probably set $debug = 1 and check the written submitfilter logs.
#!/usr/bin/perl
use strict;
use XML::Twig;
use Data::Dumper;
## Simple filter example that re-directs the output to a file.
#my $xmlinput;
my $job_user;
my $machine = "clustername";
my $debug = 0;
#Read XML from STDIN
my $xmlinput;
while(<>){
$xmlinput .= $_ ;
}
my $XMLstruct = XML::Twig->new();
$XMLstruct->parse($xmlinput);
my $root= $XMLstruct->root;
#$XMLstruct->print;
if (check_jobxml_element($root,"UserId")){
$job_user = get_jobxml_element($root,"UserId");
}
#Output original XML to file if $debug is true
#File is written into directory where msub is called
if($debug){
my $origfile = "submitfilter_" . $job_user . "_original.log";
open FILE,">>$origfile" or die "Couldn't open $origfile: $!";
my $orig_jobtext = $XMLstruct->sprint;
print FILE $orig_jobtext;
print FILE "\n";
close FILE;
}
#Add Outputfile if none specified by user
#Only for non interactive jobs
if (!check_jobxml_element($root,"Interactive")){
if (!check_jobxml_element($root,"OutputFile")){
$root->insert_new_elt('first_child', 'OutputFile', '');
my $working_dir;
if (check_jobxml_element($root,"InitialWorkingDirectory")){
$working_dir = get_jobxml_element($root,"InitialWorkingDirectory")
}
my $job_name_prefix = "_STDIN";
if (check_jobxml_element($root,"JobName")){
$job_name_prefix = "_" . get_jobxml_element($root,"JobName");
}
$root = set_jobxml_element($root,"OutputFile","$working_dir" . "/job_" . $machine . "_" . '$(JOBID)' . ".out");
}
if (!check_jobxml_element($root,"ErrorFile")){
$root->insert_new_elt('first_child', 'ErrorFile', '');
my $working_dir;
if (check_jobxml_element($root,"InitialWorkingDirectory")){
$working_dir = get_jobxml_element($root,"InitialWorkingDirectory")
}
my $job_name_prefix = "_STDIN";
if (check_jobxml_element($root,"JobName")){
$job_name_prefix = "_" . get_jobxml_element($root,"JobName");
}
$root = set_jobxml_element($root,"ErrorFile","$working_dir" . "/job_" . $machine . "_" . '$(JOBID)' . ".out");
}
}
#Set /bin/bash for interactive jobs
if (check_jobxml_element($root,"Interactive")){
if (!check_jobxml_element($root,"ShellName")){
$root->insert_new_elt('first_child', 'ShellName', '');
set_jobxml_element($root,"ShellName","/bin/bash --login");
}
}
# add Moab variables to the job's environment (see msub -E)
my $extension;
if (check_jobxml_element($root,"Extension")){
$extension = get_jobxml_element($root,"Extension");
if ($extension !~ m/x=ENVREQUESTED:TRUE/){
add_jobxml_txt_to_element($root,"Extension",";ENVREQUESTED:TRUE;");
}
}else{
$root->insert_new_elt('first_child', 'Extension', '');
$root = set_jobxml_element($root,"Extension",";x=ENVREQUESTED:TRUE;");
}
#Rewrite memory from pmem -> --slurm --mem-per-cpu
# workaround if Slurm is used as RM with Moab as scheduler
# Rewrite memory requested by msub to slurm --mem-per-cpu
#if (check_jobxml_element($root,"Memory")){
# #insert RMFlags and use msub pmem value
# $root->insert_new_elt('first_child', 'RMFlags', '');
# my $memory = get_jobxml_element($root,"Memory");
# $root = set_jobxml_element($root,"RMFlags","--mem-per-cpu=$memory");
# $root->first_child('Memory')->delete;
#
#}
## enforce user
#if (!check_jobxml_element($root,"Memory")){
# die "Please set a value for memory \n";
#}
#Output modified XML to file if ENV var SUBMITFILER_DEBUG is set
if($debug){
my $modfile = "submitfilter_" . $job_user . "_modified.log";
open FILE,">>$modfile" or die "Couldn't open $modfile: $!";
my $mod_jobtext = $XMLstruct->sprint;
print FILE "$mod_jobtext";
print FILE "\n";
close FILE;
}
#print XML to STDOUT, which will be sent to the scheduler
$XMLstruct->print;
#Some helper functions to modify XML
sub check_jobxml_element{
my $root = shift;
my $element = shift;
my $present;
if ($root->first_child($element)){
return 1;
}else{
return 0;
}
}
sub get_jobxml_element{
my $root = shift;
my $element = shift;
my $value;
$value = $root->first_child($element)->text;
return $value;
}
sub set_jobxml_element{
my $root = shift;
my $element = shift;
my $text = shift;
my $attribut = $root->first_child($element);
$attribut->set_text($text);
return $root;
}
sub add_jobxml_txt_to_element{
my $root = shift;
my $element = shift;
my $text = shift;
my $content = $root->first_child($element)->text;
$text = $content . "$text";
my $attribut = $root->first_child($element);
$attribut->set_text($text);
}
1;